Events such as slowed movements, instability, night wanders, day-night reversals, immobility can negatively affect senior wellbeing. Our goal is to improve the speed and reliability of health risk detection by taking advantage of thermal sensors and deep-learning algorithms.
Find below our research, developed in cooperation with healthcare facilities
Find below our research, developed in cooperation with healthcare facilities
Federico Polacov and Pablo Pusiol
National University of Cordoba (UNC - FaMAF)
(updated Tuesday, 20 October 2016)
National University of Cordoba (UNC - FaMAF)
(updated Tuesday, 20 October 2016)
Introduction
Our interest is to automatically detect clinically relevant daily activities of seniors living independently or in nursing homes. To do that we will use thermal information and develop innovative computer vision technology. Modern computer vision is based on deep learning techniques and has proven to be very effective at automatizing visual recognition tasks such as detecting objects in images, tracking and detecting activities in videos, etc. A caveat of these techniques is the need of big amounts of labeled data for training their models. In practice, to achieve models that could reliably work in new environments (e.g. homes, people, etc.) would require of the training dataset to contain activity examples covering the full space of the manifold defined by all possible configurations of the target activities and environments. Collecting such a dataset is hard. Human activities occurring in home settings are complex, highly variable and usually characterized with long temporal structures. This implies that the dataset of training examples would need to cover a "huge"-dimensional manifold where the many different activity variations should be present. For example, different person positions, locations in the scene, time lengths to perform an activity, variations of the sensor placement, occlusions, scene changes over time, etc. In the context of daily activities detection, collecting such a training dataset at once is hard. It might require of hundreds of data feeds for several days, or years if we consider the environmental temperature fluctuations and the different appearances (e.g. clothes) that a person will have during the stations. In addition, it would require of several human annotators working 24/7 watching and extracting the target activities appearing in the streams. Likely, the number of labelers would be proportional to the number of data streams that need to be analyzed. In addition to the complexity of collecting a big labeled training dataset, the size of each labeled example could present a problem as well. Optimizing an utility function over long-term visual streams would require a massive amount of computing power and memory.
To overcome the limitations described above, instead of thinking in rigid models to detect all activities at once it is more convenient to design dynamic systems capable of learning incrementally new activities when new labeled data arrives. Daily living activities are hierarchically composed of sub-activities occurring in a variable period of time. In general, the deeper we move in the taxonomy of activities, the less training-data is needed for building reliable models to detect them. This observation is related to the lower dimensionality of their manifold in comparison with more complex activities. We are interested in detecting complex activities in incremental bottom-up steps. First, by detecting anchoring activities lying at the lower end of the human activities taxonomy. These anchor activities are persistent human features appearing as sub-activities of more complex ones. Enabling a robust detection of these anchors will enable our second stage of learning, which will use the anchors for detecting and analyzing complex long-term human activity. For the rest of this section we will focus in the first stage of our algorithm: defining and modeling the detection of anchoring activities.
Pose Anchors
One of our anchor activities is the detection of pose. Human pose is a highly descriptive and persistent feature, capable of characterizing complex activities. For senior adults living independently, changes of pose in the particular contexts could be describing a high risk situation. For example, a person changes from "standing" to "lying in the floor" could indicate the occurrence of a fall. In nursing-homes, detecting and alerting the "coming out of bed" could enable promptly caregiver's assistance.
The detection of pose anchors is connected to the monitoring of clinically relevant activities. Here we borrow some of the target daily living activities described in http://vision.stanford.edu/pac/seniorcare/, where several of the activities presented there can be inferred directly from the human pose.
For example:
1.1. Falls: corresponds to transitions from standing to lying or from sitting to lying -as long as lying is not happening in the bed area
1.2. Front-door-Loitering: corresponds to detecting a person standing in selected locations
1.3. Day-Night-Reversals and night wanders: corresponds to detecting a person standing at unusual night hours
1.4. Sleep: corresponds to detecting a person lying in bed, even when the person is covered by a blanket
1.5. Immobility (bed or chair) corresponds to long periods of time where the person is either sitting or lying (in bed)
1.6. Restlessness: corresponds to detecting and tracking pose changes for long periods of time where the person is perpetually agitated or in motion.
Our interest is to automatically detect clinically relevant daily activities of seniors living independently or in nursing homes. To do that we will use thermal information and develop innovative computer vision technology. Modern computer vision is based on deep learning techniques and has proven to be very effective at automatizing visual recognition tasks such as detecting objects in images, tracking and detecting activities in videos, etc. A caveat of these techniques is the need of big amounts of labeled data for training their models. In practice, to achieve models that could reliably work in new environments (e.g. homes, people, etc.) would require of the training dataset to contain activity examples covering the full space of the manifold defined by all possible configurations of the target activities and environments. Collecting such a dataset is hard. Human activities occurring in home settings are complex, highly variable and usually characterized with long temporal structures. This implies that the dataset of training examples would need to cover a "huge"-dimensional manifold where the many different activity variations should be present. For example, different person positions, locations in the scene, time lengths to perform an activity, variations of the sensor placement, occlusions, scene changes over time, etc. In the context of daily activities detection, collecting such a training dataset at once is hard. It might require of hundreds of data feeds for several days, or years if we consider the environmental temperature fluctuations and the different appearances (e.g. clothes) that a person will have during the stations. In addition, it would require of several human annotators working 24/7 watching and extracting the target activities appearing in the streams. Likely, the number of labelers would be proportional to the number of data streams that need to be analyzed. In addition to the complexity of collecting a big labeled training dataset, the size of each labeled example could present a problem as well. Optimizing an utility function over long-term visual streams would require a massive amount of computing power and memory.
To overcome the limitations described above, instead of thinking in rigid models to detect all activities at once it is more convenient to design dynamic systems capable of learning incrementally new activities when new labeled data arrives. Daily living activities are hierarchically composed of sub-activities occurring in a variable period of time. In general, the deeper we move in the taxonomy of activities, the less training-data is needed for building reliable models to detect them. This observation is related to the lower dimensionality of their manifold in comparison with more complex activities. We are interested in detecting complex activities in incremental bottom-up steps. First, by detecting anchoring activities lying at the lower end of the human activities taxonomy. These anchor activities are persistent human features appearing as sub-activities of more complex ones. Enabling a robust detection of these anchors will enable our second stage of learning, which will use the anchors for detecting and analyzing complex long-term human activity. For the rest of this section we will focus in the first stage of our algorithm: defining and modeling the detection of anchoring activities.
Pose Anchors
One of our anchor activities is the detection of pose. Human pose is a highly descriptive and persistent feature, capable of characterizing complex activities. For senior adults living independently, changes of pose in the particular contexts could be describing a high risk situation. For example, a person changes from "standing" to "lying in the floor" could indicate the occurrence of a fall. In nursing-homes, detecting and alerting the "coming out of bed" could enable promptly caregiver's assistance.
The detection of pose anchors is connected to the monitoring of clinically relevant activities. Here we borrow some of the target daily living activities described in http://vision.stanford.edu/pac/seniorcare/, where several of the activities presented there can be inferred directly from the human pose.
For example:
1.1. Falls: corresponds to transitions from standing to lying or from sitting to lying -as long as lying is not happening in the bed area
1.2. Front-door-Loitering: corresponds to detecting a person standing in selected locations
1.3. Day-Night-Reversals and night wanders: corresponds to detecting a person standing at unusual night hours
1.4. Sleep: corresponds to detecting a person lying in bed, even when the person is covered by a blanket
1.5. Immobility (bed or chair) corresponds to long periods of time where the person is either sitting or lying (in bed)
1.6. Restlessness: corresponds to detecting and tracking pose changes for long periods of time where the person is perpetually agitated or in motion.
Qualitative examples. We show qualitatively results obtained by running the system in new scenes. The examples presented in the videos below are completely new to the system. We have plugged and played the system, meaning that the system has never seen the scene nor the activities of the videos in the training stage of its algorithms. Video 1 shows the time lapse video of 1 day of duration. In the scene, the bed area of an impaired male affected by vascular dementia. The frames of this video were not used for training. Similarly Video 2 shows an impaired male person of 81 years old suffering a visual impairment. The labels appearing at the top left of the videos are automatically detected by our algorithm.
|
|
|
|
Classifying all 5 activities at once
Classes: background, standing, sitting, lying, people Evaluation. The dataset was split into training and testing datasets, 80%/20% respectively. We are careful of not including any frame of a testing video in the training set (and vice versa). Training was done for 500 epochs. Our dataset is composed of exactly 5055 frames per class. Results were obtained running the algorithm in the validation dataset, showing a generalization error of 7.09 %. 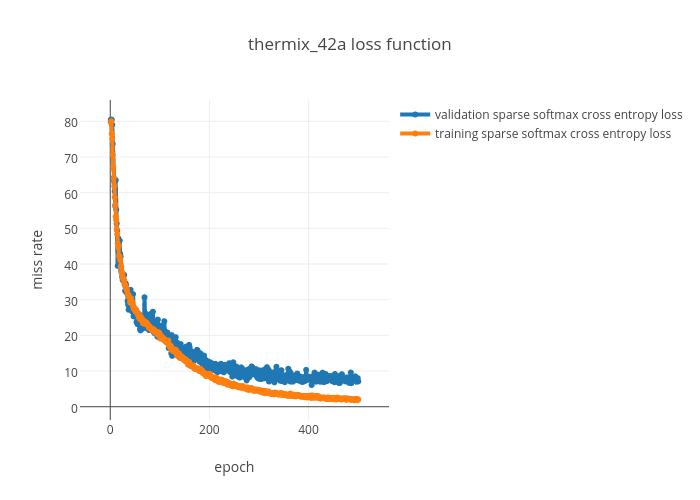
|
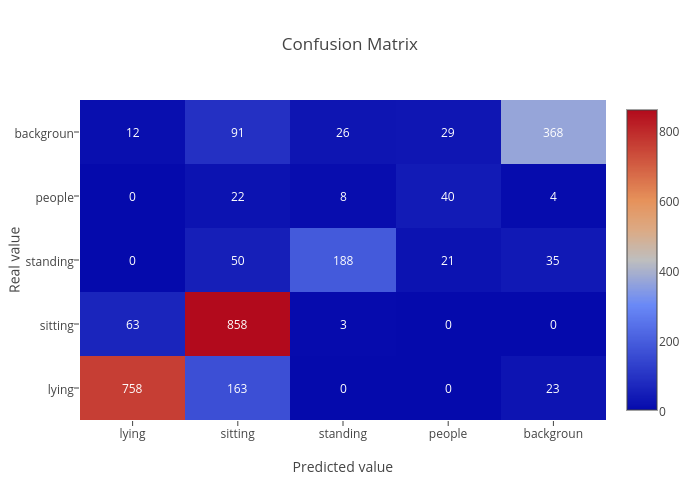
Confusion matrix of 5 classes in a testing dataset with chunks from Thermset.
|
Validation data. The five videos below contain the 20% left out of the training dataset from where the confusion matrix and validation cross entropy loss was calculated. Each frame has its prediction at top left.
|
Lying
|
Sitting
|
Standing
|
People
|
Background
|
Cascade activity classification for optimizing resources
Real-world deployed systems need to consider the inherent limitations of technology. In particular the tradeoff between utility speed, computation power, cost and accuracy of the system. The deployment of the system needs to take into account that common people and nursing homes don't have high internet bandwidth, in many cases they don't have internet at all.
It is frequent that more several people appears in the scene: caregivers assisting elders in preparing for bed, standing up, getting dressed, etc. The detection of poses simultaneously of multiple people acting in the scene is not the goal of this work since high risk situations usually occur when a person is alone without caregiver's supervision. We can avoid the intrinsic complexities of identifying and localizing a target senior in multi-people situations. Considering this, we propose a cascade system of two detection steps. In -Step 1-, an algorithm is trained to detect the presence of people in the scene. If the senior is alone, Stage 2 is activated. In -Step 2-, an algorithm will refine the previous stage by detecting senior's pose.
Real-world deployed systems need to consider the inherent limitations of technology. In particular the tradeoff between utility speed, computation power, cost and accuracy of the system. The deployment of the system needs to take into account that common people and nursing homes don't have high internet bandwidth, in many cases they don't have internet at all.
It is frequent that more several people appears in the scene: caregivers assisting elders in preparing for bed, standing up, getting dressed, etc. The detection of poses simultaneously of multiple people acting in the scene is not the goal of this work since high risk situations usually occur when a person is alone without caregiver's supervision. We can avoid the intrinsic complexities of identifying and localizing a target senior in multi-people situations. Considering this, we propose a cascade system of two detection steps. In -Step 1-, an algorithm is trained to detect the presence of people in the scene. If the senior is alone, Stage 2 is activated. In -Step 2-, an algorithm will refine the previous stage by detecting senior's pose.
Detecting: person, people and background -Step 1-
Evaluation. On the 20% of data left out of training, shown above as validation data, our model achieves the following evaluation metrics, where positive is presence of at least a person in the scene:
Evaluation. On the 20% of data left out of training, shown above as validation data, our model achieves the following evaluation metrics, where positive is presence of at least a person in the scene:
- accuracy: 98.20 %
- sensitivity (recall, true positive rate): 98.97 %
- specificity (true negative rate): 95.05 %
- precision (positive predictive value) : 98.78 %
- negative predictive value: 95.81 %
- fall-out (false positive rate): 4.95 %
- miss-rate (false negative rate): 1.03 %
- false-discovery-rate: 1.22 %
The video shown on the right contains 4 days of footage of a 93 years old female with mobility limitations. In the video, the background frames were removed automatically to help with the video visualization.
|
Detecting: standing, sitting and lying -Step 2-
Evaluation. We randomly split 80%/20% of gathered data into training and testing datasets. Since our training units are videos, we are careful of not including any frame of a testing video in the training set (and vice versa). Training was done for 1500 epochs. Our training dataset is composed of exactly 3123 frames per class. Results. Figure 2 shows the training and validation results for several epochs. At epoch 1500 the average generalization error between the 3 classes is 8.53% and the training error is 0.17%. |
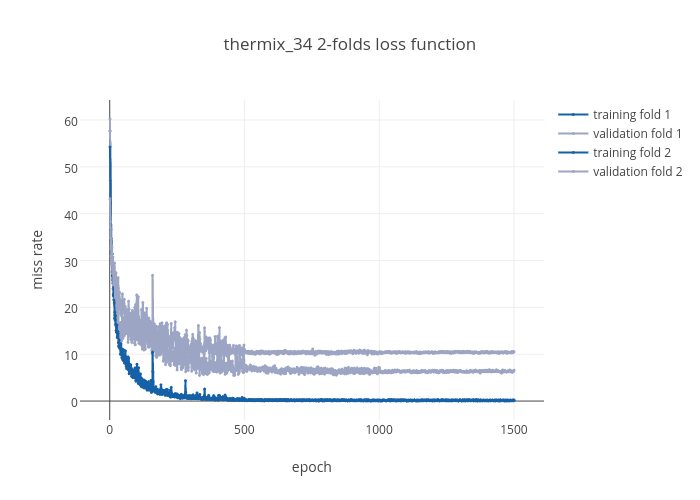
Figure2. Training and Test error rate of the model of -Stage 2-. Our error function is sparse cross entropy for logits.
|
Dataset (08/19/2016). The five videos below contain the dataset for each target class. We are working with the absolute temperature value of the thermal sensor, so images were stretched to ease visualization.
|
|
|
|
|
|
|
